Při práci byste měli vždy vědět, na jakém typu Datového zdroje je analýza postavená: v případě Přímého datového zdroje máte jistotu, že v reálném čase pracujete s aktuálními údaji (zdroj čerpá data přímo z Money ERP), avšak v případě datového zdroje MS Analysis Services (OLAP) jsou data uložená v podobě datové kostky na serveru a při práci je podle potřeby nutné provádět jejich aktualizaci (funkcí Obnovit data).
Karta analýzy je rozdělená na tři části: nahoře je standardní nástrojová lišta s tlačítky, pod ní je část s vlastní analýzou v podobě tzv. pivot tabulky a dole je možné zobrazit graf.
Nástrojová lišta
![]() Uložit jako – pokud chcete pro další použití zachovat jakékoliv změny provedené v analýze, případně si nechcete zrušit nastavení stávající analýzy, stačí stisknout tlačítko a zadat nový název. Původní analýza zůstane uložená beze změny a vy nadále pracujete s novou analýzou. Jestliže ji následně uložíte tlačítkem OK, zařadí se do seznamu analýz jako samostatná položka.
Uložit jako – pokud chcete pro další použití zachovat jakékoliv změny provedené v analýze, případně si nechcete zrušit nastavení stávající analýzy, stačí stisknout tlačítko a zadat nový název. Původní analýza zůstane uložená beze změny a vy nadále pracujete s novou analýzou. Jestliže ji následně uložíte tlačítkem OK, zařadí se do seznamu analýz jako samostatná položka.
![]() Filtr – tlačítkem otevřete přehled Filtrů, které jste si vytvořili na poslední straně průvodce při založení analýzy. Filtry můžete libovolně uplatňovat zatržením.
Filtr – tlačítkem otevřete přehled Filtrů, které jste si vytvořili na poslední straně průvodce při založení analýzy. Filtry můžete libovolně uplatňovat zatržením.
![]() Obnovit data – refresh je nezbytně nutné používat pro obnovení dat z datového zdroje v případě, že je analýza založená na zdroji MS Analysis Services (OLAP).
Obnovit data – refresh je nezbytně nutné používat pro obnovení dat z datového zdroje v případě, že je analýza založená na zdroji MS Analysis Services (OLAP).
![]() Editovat analýzu – tlačítko otevře Průvodce vytvořením nové analýzy, kde můžete změnit výběr zobrazovaných sloupců. Pozor – výběr se neupravuje, ale provádí se znovu od začátku, do části Vybrané sloupce tedy musíte přenést všechny sloupce, které chcete v analýze vidět. Nastavení výběru sloupců je výhodné spojit s funkcí Uložit jako, kdy se analýza s jiným výběrem uloží pod jiným jménem.
Editovat analýzu – tlačítko otevře Průvodce vytvořením nové analýzy, kde můžete změnit výběr zobrazovaných sloupců. Pozor – výběr se neupravuje, ale provádí se znovu od začátku, do části Vybrané sloupce tedy musíte přenést všechny sloupce, které chcete v analýze vidět. Nastavení výběru sloupců je výhodné spojit s funkcí Uložit jako, kdy se analýza s jiným výběrem uloží pod jiným jménem.
![]() Nastavení – roletová nabídka dává možnost zobrazovat různé úrovně součtování dat:
Nastavení – roletová nabídka dává možnost zobrazovat různé úrovně součtování dat:
![]() Zobrazovat meziřádkové/mezisloupcové součty – má význam v případě, kdy se řádky/sloupce seskupují do nadřazených dimenzí (např. rok se dělí na čtvrtletí a na měsíce) a vy chcete v analýze vidět i součty nadřízených dimenzí (za čtvrtletí a rok). Součtové řádky/sloupce jsou podbarvené žlutě.
Zobrazovat meziřádkové/mezisloupcové součty – má význam v případě, kdy se řádky/sloupce seskupují do nadřazených dimenzí (např. rok se dělí na čtvrtletí a na měsíce) a vy chcete v analýze vidět i součty nadřízených dimenzí (za čtvrtletí a rok). Součtové řádky/sloupce jsou podbarvené žlutě.
![]() Zobrazovat součty pro samostatné hodnoty – pokud se řádky nebo sloupce nerozpadají na podřízené dimenze, předchozí volbou jejich "součet" nezobrazíte, neboť by se zde uváděly identické hodnoty. Jestliže i přesto potřebujete tyto součtové řádky/sloupce vidět, volbu zatrhněte.
Zobrazovat součty pro samostatné hodnoty – pokud se řádky nebo sloupce nerozpadají na podřízené dimenze, předchozí volbou jejich "součet" nezobrazíte, neboť by se zde uváděly identické hodnoty. Jestliže i přesto potřebujete tyto součtové řádky/sloupce vidět, volbu zatrhněte.
![]() Zobrazovat součty za hodnotami – výsledné součty se standardně zobrazují za hodnotami, které jsou předmětem součtování. Není-li volba aktivní, zobrazují se před nimi.
Zobrazovat součty za hodnotami – výsledné součty se standardně zobrazují za hodnotami, které jsou předmětem součtování. Není-li volba aktivní, zobrazují se před nimi.
![]() XLS – načtená data se dají uložit i v podobě excelovské tabulky, kterou je možné nadále libovolně upravovat (provádět součty apod.). Tlačítko nabízí tři varianty exportu:
XLS – načtená data se dají uložit i v podobě excelovské tabulky, kterou je možné nadále libovolně upravovat (provádět součty apod.). Tlačítko nabízí tři varianty exportu:
![]() XLS – výsledný soubor kopíruje co nejvíce vzhled zobrazených dat, které exportuje včetně grafických prvků (metoda WYSIWYG, tedy What You See Is What You Get). V tabulce se v tomto případě zobrazí i sloučené buňky platné pro několik řádků nebo sloupců.
XLS – výsledný soubor kopíruje co nejvíce vzhled zobrazených dat, které exportuje včetně grafických prvků (metoda WYSIWYG, tedy What You See Is What You Get). V tabulce se v tomto případě zobrazí i sloučené buňky platné pro několik řádků nebo sloupců.
![]() XLS (data) – tento režim je export optimalizovaný pro následnou analýzu dat kontingenční tabulky a využijete jej tedy v případě, kdy s daty potřebujete dále pracovat (např. filtrovat opakující se hodnoty). Všechna sloučená pole se rozepíšou do jednotlivých buněk.
XLS (data) – tento režim je export optimalizovaný pro následnou analýzu dat kontingenční tabulky a využijete jej tedy v případě, kdy s daty potřebujete dále pracovat (např. filtrovat opakující se hodnoty). Všechna sloučená pole se rozepíšou do jednotlivých buněk.
![]() CSV – také tento typ exportu má zobrazení dat optimalizované pro následnou analýzu – vynechávají se nepoužitá pole, nedochází ke slučování buněk a hodnoty se převedou bez formátování.
CSV – také tento typ exportu má zobrazení dat optimalizované pro následnou analýzu – vynechávají se nepoužitá pole, nedochází ke slučování buněk a hodnoty se převedou bez formátování.
![]() Graf – standardní nastavení je Žádný graf. Z roletové nabídky lze vybrat některý z mnoha různých způsobů zobrazení a tlačítkem Možnosti grafu můžete jejich podobu editovat. Bližší popis najdete dále v kapitole Graf.
Graf – standardní nastavení je Žádný graf. Z roletové nabídky lze vybrat některý z mnoha různých způsobů zobrazení a tlačítkem Možnosti grafu můžete jejich podobu editovat. Bližší popis najdete dále v kapitole Graf.
Pivot tabulka
Pod nástrojovou lištou je zobrazená Pivot tabulka (speciální typ tabulky používaný pro vyhodnocování dat), ve které pracujete s vlastními údaji datového zdroje. Ve formě Datových polí jsou zde všechny Vybrané sloupce, které jste zvolili při Editaci analýzy, a to v podobě a na místech, jaké jste definovali při Mapování sloupců v případě přímého datového zdroje, nebo v Datové kostce datového zdroje OLAP. Datová pole se podle charakteru dělí na dva základní druhy:
![]() Dimenze – tato data představují nezávislou proměnnou (např. datum, seznam partnerů) a v analýze se umísťují do záhlaví řádků nebo sloupců.
Dimenze – tato data představují nezávislou proměnnou (např. datum, seznam partnerů) a v analýze se umísťují do záhlaví řádků nebo sloupců.
![]() Měřítka – představují závislou proměnnou (částka na faktuře, která se vztahuje k datu vystavení a partnerovi), v analýze jsou uvedené jako jednotlivé buňky tabulky. Měřítko se pozná podle schopnosti sčítat jeho hodnoty.
Měřítka – představují závislou proměnnou (částka na faktuře, která se vztahuje k datu vystavení a partnerovi), v analýze jsou uvedené jako jednotlivé buňky tabulky. Měřítko se pozná podle schopnosti sčítat jeho hodnoty.
![]() Ve výjimečných případech mohou data představovat dimenzi i měřítko současně. Např. číslo faktury je téměř vždy dimenzí, ale někdy jej lze uvádět i jako měřítko.
Ve výjimečných případech mohou data představovat dimenzi i měřítko současně. Např. číslo faktury je téměř vždy dimenzí, ale někdy jej lze uvádět i jako měřítko.
Podle nastavení vlastností a mapování sloupců v Datovém zdroji jsou při prvním spuštění analýzy datová pole umístěná v pivot tabulce do následujících oblastí:
![]() Oblast pro nepoužitá datová pole – v horním řádku tabulky jsou uvedené všechny dimenze i měřítka, které aktuálně nebyly k sestavení analýzy použité.
Oblast pro nepoužitá datová pole – v horním řádku tabulky jsou uvedené všechny dimenze i měřítka, které aktuálně nebyly k sestavení analýzy použité.
![]() Oblast pro umístění dimenzí do řádků/sloupců – datová pole definovaná jako dimenze, která byla použitá k sestavení řádků/sloupců tabulky, jsou umístěná v záhlaví řádků nebo sloupců.
Oblast pro umístění dimenzí do řádků/sloupců – datová pole definovaná jako dimenze, která byla použitá k sestavení řádků/sloupců tabulky, jsou umístěná v záhlaví řádků nebo sloupců.
![]() Oblast pro umístění měřítek – datová pole ve formě měřítek (jejich data tvoří buňky tabulky), mají název umístěný v prostoru mezi záhlavím sloupců a řádků.
Oblast pro umístění měřítek – datová pole ve formě měřítek (jejich data tvoří buňky tabulky), mají název umístěný v prostoru mezi záhlavím sloupců a řádků.
![]() Prázdná oblast (bez jediného umístěného datového pole) obsahuje popis, pro jaký typ datových polí slouží. Pokud tedy nemáte v rozmístění oblastí jasno, přesuňte si myší datová pole jinam. Podrobnější popis oblastí včetně ilustračních obrázků najdete také v PDF Business Intelligence, který je k dispozici na Zákaznickém portálu v části Dokumentace.
Prázdná oblast (bez jediného umístěného datového pole) obsahuje popis, pro jaký typ datových polí slouží. Pokud tedy nemáte v rozmístění oblastí jasno, přesuňte si myší datová pole jinam. Podrobnější popis oblastí včetně ilustračních obrázků najdete také v PDF Business Intelligence, který je k dispozici na Zákaznickém portálu v části Dokumentace.
Mezi jednotlivými oblastmi se datová pole dají libovolně přesouvat pouhým přetažením myší, samozřejmě jen v rámci použitelnosti (dimenze výhradně do oblasti pro umístění dimenzí a měřítka do oblasti pro měřítka). Jejich pozice v příslušné oblasti přímo ovlivní podobu tabulky (přesunem na jinou pozici změníte systém třídění tabulky). Nepotřebná pole jde přetáhnout zpět do oblasti pro nevyužitá pole. Tabulka se po každém přesunu polí ihned překreslí a její hodnoty se přepočítají.
Pro získání údajů nabízí pivot tabulka řadu dalších funkcí:
![]() Seskupování dimenzí – jak již bylo uvedeno dříve, pomocí levého tlačítka myši se datová pole dají přesouvat. Zařadíte-li více dimenzí do oblasti pro umístění do řádků/sloupců, údaje v tabulce se hierarchicky seskupují podle podobnosti dat získaných z datového zdroje. Jestliže tedy na výše uvedeném obrázku přetáhnete do oblasti pro umístění dimenzí do sloupců také dosud nepoužitá datová pole pro Datum vystavení – čtvrtletí a Datum vystavení – měsíc, budou částky v tabulce rozpočteny na jednotlivé měsíce (s případnými mezisoučty za čtvrtletí a roky). Přitom je důležité seřadit datová pole podle požadované hierarchie, tj. zleva doprava rok–čtvrtletí–měsíc.
Seskupování dimenzí – jak již bylo uvedeno dříve, pomocí levého tlačítka myši se datová pole dají přesouvat. Zařadíte-li více dimenzí do oblasti pro umístění do řádků/sloupců, údaje v tabulce se hierarchicky seskupují podle podobnosti dat získaných z datového zdroje. Jestliže tedy na výše uvedeném obrázku přetáhnete do oblasti pro umístění dimenzí do sloupců také dosud nepoužitá datová pole pro Datum vystavení – čtvrtletí a Datum vystavení – měsíc, budou částky v tabulce rozpočteny na jednotlivé měsíce (s případnými mezisoučty za čtvrtletí a roky). Přitom je důležité seřadit datová pole podle požadované hierarchie, tj. zleva doprava rok–čtvrtletí–měsíc.
![]() Rozbalení/sbalení seskupených dimenzí – hierarchicky seskupené dimenze se poklepáním myší na ikonku +/– dají rozbalovat/sbalovat, tj. zobrazovat/skrývat podřízené dimenze (měsíce, čtvrtletí). Jde o obdobu funkce z Nastavení analýzy Zobrazovat součty, kdy získáte rychlý přehled o nadřazených hodnotách (součtech za čtvrtletí, rok).
Rozbalení/sbalení seskupených dimenzí – hierarchicky seskupené dimenze se poklepáním myší na ikonku +/– dají rozbalovat/sbalovat, tj. zobrazovat/skrývat podřízené dimenze (měsíce, čtvrtletí). Jde o obdobu funkce z Nastavení analýzy Zobrazovat součty, kdy získáte rychlý přehled o nadřazených hodnotách (součtech za čtvrtletí, rok).
![]() Řazení hodnot datových polí – každé použité datové pole je opatřené ikonou šipky
Řazení hodnot datových polí – každé použité datové pole je opatřené ikonou šipky ![]() , která určuje způsob abecedního řazení – poklepáním na šipku se řazení obrátí.
, která určuje způsob abecedního řazení – poklepáním na šipku se řazení obrátí.
![]() Výběr hodnot datových polí – další ikona v podobě klíče
Výběr hodnot datových polí – další ikona v podobě klíče ![]() na datovém poli otevře po poklepání myší okno pro výběr zobrazených hodnot. Datové pole obsahuje množinu hodnot přebraných z datového zdroje (např. Datum vystavení – rok obsahuje seznam účetních roků agendy). Standardně jsou všechny hodnoty zobrazené, ale v okně pro výběr hodnot se dají nepotřebné údaje skrýt.
na datovém poli otevře po poklepání myší okno pro výběr zobrazených hodnot. Datové pole obsahuje množinu hodnot přebraných z datového zdroje (např. Datum vystavení – rok obsahuje seznam účetních roků agendy). Standardně jsou všechny hodnoty zobrazené, ale v okně pro výběr hodnot se dají nepotřebné údaje skrýt.
![]() Detail buňky – toto okno obsahují jen analýzy založené na přímém datovém zdroji. Otevřete jej poklepáním levého tlačítka myši na buňce tabulky a najdete v něm seznam všech hodnot, které byly z přímého datového zdroje použité pro tvorbu buňky – tedy např. všechny faktury z Money ERP, které dohromady tvoří součet částek uvedený v buňce. Jednotlivé zdrojové položky si můžete v okně Detail buňky zobrazit pomocí místní nabídky. Také okno pro Detail buňky funguje jako pivot tabulka, to znamená, že jeho datová pole je možné přetažením myší seskupovat, a také jejich hodnoty vybírat či řadit, jak je popsáno výše.
Detail buňky – toto okno obsahují jen analýzy založené na přímém datovém zdroji. Otevřete jej poklepáním levého tlačítka myši na buňce tabulky a najdete v něm seznam všech hodnot, které byly z přímého datového zdroje použité pro tvorbu buňky – tedy např. všechny faktury z Money ERP, které dohromady tvoří součet částek uvedený v buňce. Jednotlivé zdrojové položky si můžete v okně Detail buňky zobrazit pomocí místní nabídky. Také okno pro Detail buňky funguje jako pivot tabulka, to znamená, že jeho datová pole je možné přetažením myší seskupovat, a také jejich hodnoty vybírat či řadit, jak je popsáno výše.
Další možnosti ovládání najdete v místní nabídce otevřené pravým tlačítkem myši na datovém poli:
![]() Zobrazit seznam datových polí – v určitých situacích je vhodné některá datová pole z oblasti analýzy odstranit úplně. Volbou místní nabídky otevřete seznam skrytých datových polí, kam je možné myší přetahovat pole z pivot tabulky, případně je vracet zpět.
Zobrazit seznam datových polí – v určitých situacích je vhodné některá datová pole z oblasti analýzy odstranit úplně. Volbou místní nabídky otevřete seznam skrytých datových polí, kam je možné myší přetahovat pole z pivot tabulky, případně je vracet zpět.
![]() Zobrazit filtrování dat – vedle Filtrování dat analýzy nabízí místní nabídka i přímé filtrování hodnot datových polí. Jde o standardní filtr, kde ikonou
Zobrazit filtrování dat – vedle Filtrování dat analýzy nabízí místní nabídka i přímé filtrování hodnot datových polí. Jde o standardní filtr, kde ikonou ![]() přidáváte podmínky a ikonou
přidáváte podmínky a ikonou ![]() je odebíráte. Podmínka se skládá ze tří položek: datové pole, operátor (začíná na, je rovno, je větší než, obsahuje, je prázdné apod.) a hodnota. Všechny položky můžete vybrat z roletové nabídky, hodnotu lze i přímo zapsat. Vztah mezi podmínkami je standardně určený spojovacím operátorem A zároveň
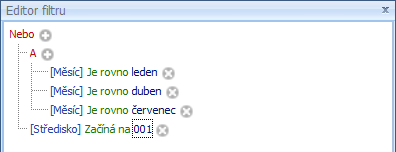
je odebíráte. Podmínka se skládá ze tří položek: datové pole, operátor (začíná na, je rovno, je větší než, obsahuje, je prázdné apod.) a hodnota. Všechny položky můžete vybrat z roletové nabídky, hodnotu lze i přímo zapsat. Vztah mezi podmínkami je standardně určený spojovacím operátorem A zároveň ![]() . Poklepáním na něj otevřete výběrové okno, kde můžete vybrat jiný spojovací operátor (nebo, negace atd.), přidat podskupinu s vlastním operátorem apod. Operátor se vztahuje ke všem podřízeným položkám v následující úrovni. Pokud chcete operátory kombinovat, musíte je nastavit „shora“ tak, aby byl potřebný operátor vždy v kořeni těch podmínek, které má ovlivnit. Pokud například chcete, aby filtr vybral položky, které se vyskytují současně ve třech konkrétní měsících (operátor A), a spolu s nimi i všechny, které bez ohledu na období spadají do určitého okruhu středisek (operátor Nebo), zadejte filtr následujícím způsobem:
. Poklepáním na něj otevřete výběrové okno, kde můžete vybrat jiný spojovací operátor (nebo, negace atd.), přidat podskupinu s vlastním operátorem apod. Operátor se vztahuje ke všem podřízeným položkám v následující úrovni. Pokud chcete operátory kombinovat, musíte je nastavit „shora“ tak, aby byl potřebný operátor vždy v kořeni těch podmínek, které má ovlivnit. Pokud například chcete, aby filtr vybral položky, které se vyskytují současně ve třech konkrétní měsících (operátor A), a spolu s nimi i všechny, které bez ohledu na období spadají do určitého okruhu středisek (operátor Nebo), zadejte filtr následujícím způsobem:
![]() V případě analýz, které pracují s časovým rozmezím – např. analýza Zakázky – je možné filtrovat časové údaje s libovolným složením intervalů, které jsou navržené tak, že každý následující vždy přesně navazuje na předcházející úsek. Datové pole nabízí k výběru relativní časové úseky (vztažené k systémovému datu počítače, nikoliv k pracovnímu datu Money ERP), které se dají na kartě Filtrování dat pivot tabulky poskládat tak, že mohou zahrnout libovolný sled přerušovaných období. Pokud chcete filtrovat delší časový úsek zahrnující několik navazujících intervalů, musíte je do filtru vložit všechny. Princip si vysvětlíme na příkladu filtru použitého ve čtvrtek 16. 5. 2019.
V případě analýz, které pracují s časovým rozmezím – např. analýza Zakázky – je možné filtrovat časové údaje s libovolným složením intervalů, které jsou navržené tak, že každý následující vždy přesně navazuje na předcházející úsek. Datové pole nabízí k výběru relativní časové úseky (vztažené k systémovému datu počítače, nikoliv k pracovnímu datu Money ERP), které se dají na kartě Filtrování dat pivot tabulky poskládat tak, že mohou zahrnout libovolný sled přerušovaných období. Pokud chcete filtrovat delší časový úsek zahrnující několik navazujících intervalů, musíte je do filtru vložit všechny. Princip si vysvětlíme na příkladu filtru použitého ve čtvrtek 16. 5. 2019.
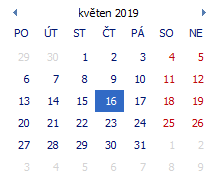
Intervaly, které v takovém případě budou představovat jednotlivá datová pole, budou následující (veškerá data platí včetně uvedeného dne):
![]() Je v minulém roce a dříve – období nemá začátek a končí 31. 12. 2018 (konec předcházejícího roku)
Je v minulém roce a dříve – období nemá začátek a končí 31. 12. 2018 (konec předcházejícího roku)
![]() Je dříve v tomto roce – začíná 1. 1. 2019 a končí 30. 4. 2019 (začátek tohoto roku až konec předcházejícího měsíce)
Je dříve v tomto roce – začíná 1. 1. 2019 a končí 30. 4. 2019 (začátek tohoto roku až konec předcházejícího měsíce)
![]() Je dříve v tomto měsíci – začíná 1. 5. 2019 a končí 5. 5. 2019 (začátek tohoto měsíce až konec předminulého týdne)
Je dříve v tomto měsíci – začíná 1. 5. 2019 a končí 5. 5. 2019 (začátek tohoto měsíce až konec předminulého týdne)
![]() Je minulý týden – začíná 6. 5. 2019 a končí 12. 5. 2019 (celý minulý týden)
Je minulý týden – začíná 6. 5. 2019 a končí 12. 5. 2019 (celý minulý týden)
![]() Je dříve v tomto týdnu – začíná 13. 5. 2019 a končí 14. 5. 2019 (začátek tohoto týdne až předevčírem)
Je dříve v tomto týdnu – začíná 13. 5. 2019 a končí 14. 5. 2019 (začátek tohoto týdne až předevčírem)
![]() Je včera – 15. 5. 2019
Je včera – 15. 5. 2019
![]() Je dnes – 16. 5. 2019
Je dnes – 16. 5. 2019
![]() Je zítra – 17. 5. 2019
Je zítra – 17. 5. 2019
![]() Je později v tomto týdnu – začíná 18. 5. 2019 a končí 19. 5. 2019 (pozítří až konec tohoto týdne)
Je později v tomto týdnu – začíná 18. 5. 2019 a končí 19. 5. 2019 (pozítří až konec tohoto týdne)
![]() Je příští týden – začíná 20. 5. 2019 a končí 26. 5. 2019 (celý příští týden)
Je příští týden – začíná 20. 5. 2019 a končí 26. 5. 2019 (celý příští týden)
![]() Je později v tomto měsíci – začíná 27. 5. 2019 a končí 31. 5. 2019 (začátek přespříštího týdne až konec tohoto měsíce)
Je později v tomto měsíci – začíná 27. 5. 2019 a končí 31. 5. 2019 (začátek přespříštího týdne až konec tohoto měsíce)
![]() Je později v tomto roce – začíná 1. 6. 2019 a končí 31. 12. 2019 (začátek příštího měsíce až konec tohoto roku)
Je později v tomto roce – začíná 1. 6. 2019 a končí 31. 12. 2019 (začátek příštího měsíce až konec tohoto roku)
![]() Je v příštím roce a později – období začíná 1. 1. 2020 (začátek příštího roku) a nemá konec
Je v příštím roce a později – období začíná 1. 1. 2020 (začátek příštího roku) a nemá konec
Jestliže chcete do analýzy zahrnout záznamy, spadající do časového období např. od zítřka do konce měsíce, musíte si do filtru vybrat všechny položky, které tento časový úsek představují: Je zítra, Je později v tomto týdnu, Je příští týden a Je později v tomto měsíci. Spojovací operátor mezi nimi musí být Nebo.
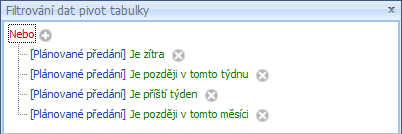
V analýze se pak zobrazí položky spadající do časového intervalu 17. 5. 2019 – 31. 5. 2019.
Graf
Důležitou součástí každé analýzy je grafický výstup, který umožní rychle zhodnotit analyzované údaje. Graficky se znázorní vždy jen ta část tabulky, jejíž buňky označíte (myš se stisknutým levým tlačítkem táhnete přes záhlaví řádků/sloupců, nebo přímo přes požadovanou oblast buněk). Program nabízí velmi širokou škálu různých zobrazení, která lze vybrat z roletové nabídky umístěné na nástrojové liště. 3D grafy se dají myší libovolně natáčet.
Grafické zobrazení vypnete volbou Žádný graf.
Vedle volby zobrazení je pak na nástrojové liště umístěné tlačítko Možnosti grafu, které nabízí řadu dalších upřesnění:
![]() Prohodit osy – standardně se na horizontální osu (X) umísťují hodnoty dimenzí v řádcích a na vertikální (Y) ve sloupcích. Podle potřeby lze umístění hodnot na osách vyměnit.
Prohodit osy – standardně se na horizontální osu (X) umísťují hodnoty dimenzí v řádcích a na vertikální (Y) ve sloupcích. Podle potřeby lze umístění hodnot na osách vyměnit.
![]() Považovat nedefinované hodnoty za nuly – nedefinované hodnoty mohou v pivot tabulce způsobit nespojitosti v grafu, proto je někdy lepší je považovat za nulové.
Považovat nedefinované hodnoty za nuly – nedefinované hodnoty mohou v pivot tabulce způsobit nespojitosti v grafu, proto je někdy lepší je považovat za nulové.
![]() Skrýt popisky v grafu – graf vzniklý zobrazením složitější tabulky může obsahovat takové množství popisů, že se stane nepřehledným. Pokud popisky skryjete, hodnoty se zobrazí po umístění myši nad příslušnou část grafu.
Skrýt popisky v grafu – graf vzniklý zobrazením složitější tabulky může obsahovat takové množství popisů, že se stane nepřehledným. Pokud popisky skryjete, hodnoty se zobrazí po umístění myši nad příslušnou část grafu.
![]() Uzamknou graf – nezamčený graf vždy zobrazuje aktuální hodnoty v tabulce, což znamená, že je při každé změně okamžitě překreslen. V případě, že chcete podobu grafu uchovat, zamkněte jej.
Uzamknou graf – nezamčený graf vždy zobrazuje aktuální hodnoty v tabulce, což znamená, že je při každé změně okamžitě překreslen. V případě, že chcete podobu grafu uchovat, zamkněte jej.
![]() Tisk grafu s náhledem – tisk s náhledem nabízí, tak jako v dalších částech programu, řadu možností: opatřit graf záhlavím nebo vodoznakem, změnit barvu pozadí, tisknout jej naležato, uložit nebo odeslat mailem atd.
Tisk grafu s náhledem – tisk s náhledem nabízí, tak jako v dalších částech programu, řadu možností: opatřit graf záhlavím nebo vodoznakem, změnit barvu pozadí, tisknout jej naležato, uložit nebo odeslat mailem atd.